有很多指标可以衡量机器学习模型的效果,不同的任务使用的评价指标也不尽相同。本文对二分类任务的评价指标加以总结。全文系作者原创,仅供学习参考使用,转载授权请私信联系,否则将视为侵权行为。码字不易,感谢支持。
在二分类问题中,数据的标签通常用(0/1)来表示,在模型训练完成后进行测试时,会对测试集的每个样本计算一个介于0~1之间的概率,表征模型认为该样本为阳性的概率,我们可以选定一个阈值,将模型计算出的概率进行二值化,比如选定阈值=0.5,那么当模型输出的值大于等于0.5时,我们就认为模型将该样本预测为阳性,也就是标签为1,反之亦然。选定的阈值不同,模型预测的结果也会相应地改变。二元分类模型的单个样本预测有四种结果:
- 真阳性(TP):判断为阳性,实际也是阳性。
- 伪阳性(FP):判断为阳性,实际却是阴性。
- 真阴性(TN):判断为阴性,实际也是阴性。
- 伪阴性(FN):判断为阴性,实际却是阳性。
这四种结果可以画成2 × 2的混淆矩阵:
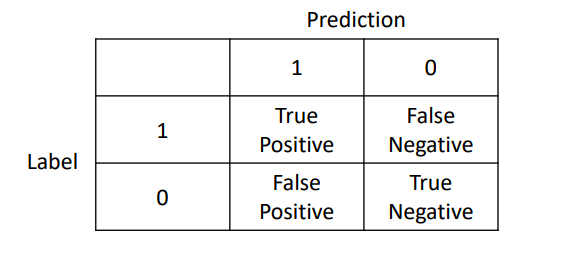
有了混淆矩阵,就可以定义各种指标了。
- TPR(真阳性率) = TP / (TP + FN)
- FPR(假阳性率) = FP / (FP + TN)
- Accuracy(准确率)= (TP + TN) / (TP+TN+FP+FN)
- Precision(精确率)= TP / (TP + FP)
- Recall(召回率)= TP / (TP + FN)
- F1值 = 2TP / (2TP+FP+FN)
- PPV(positive predictive value)= TP / (TP + FP)
- sensitivity(敏感性)= TP / (TP + FN)
- specificity(特异性)= TN / (TN + FP)
以上就是本文的全部内容,如果您喜欢这篇文章,欢迎将它分享给朋友们。
感谢您的阅读,祝您生活愉快!
作者:小美哥
2018-06-12
